【BigData Key Skills】: Part 2. Subset Data

As a data scientist, it is very often to subset data or slice data. Generally speaking, there are two ways in slicing data: vertically and horizontally. Let’s address the vertical subset first.
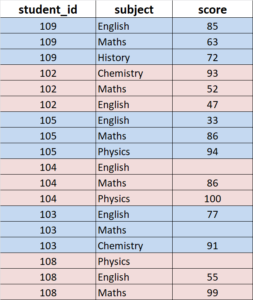
Subset data vertically
It means that we want to reduce the length of a data table, namely, reduce the number of rows or records. Using the above example data, we can filter records in SAS, SQL, R, Python as below respectively.
SAS/SQL
Provided that we want to look at the data of students who pass English test, we can use below SAS or SQL code to do it. In this way, the output data has only 2 records, but with the same number of columns. Only the length of data table is reduced. In DATA step, we can use either WHERE or IF statement to perform the task, but WHERE is preferred because it is a compile command and therefore has higher processing efficiency. However, in SQL, we can only use WHERE to subset data.
data Subset;
set Score;
where Subject='English' and Score>=60;
* if Subject='English' and Score>=60;
run;
proc sql;
create table Subset as
from Score
where Subject='English' and Score>60;
quit;Code language: SAS (sas)R
As its name suggests, filter() function in the dplyr library is developed to slice data vertically. It is very straightforward and easy to use, we give the equivalent R syntax below, which produces the same results as SAS code.
subset<- score %>% filter(subject=='English' & score]>=60)Code language: R (r)Please note: In R, we must use double equal sign “==” for Boolean logic, a single equal sign is not allowed and will lead to an error. Also, the “&” and “|” are used for AND and OR operations respectively.
Python
Python provides several options to slice data vertically such as indexing, loc[], iloc[], query() functions. We focus on pandas library and give the syntax for using pandas functions. query() function is derived from SQL language, but its syntax is much more concise than the loc[] and iloc[] functions.
subset=score.loc[:,(score['subject']=='English')& score['score']>=60]
subset=score.query(" subject=='English' & score>=60 ")Code language: Python (python)Subset data horizontally
This subset approach is mainly aimed to reduce the number of columns, i.e., to drop some variables or keep the needed variables.
SAS/SQL
SAS provides many convenient options to slice data horizontally, we can use either KEEP/DROP statements or KEEP/DROP options. Some example syntax is given below. Unfortunately, in native SQL languages, DROP option is NOT available, therefore we can only use SELECT statement to choose the wanted variables. Sometimes it is really inconvenient in our work.
data Subset;
*** data Subset(keep= Student_ID Score);
set Score;
*** set Score(keep=Student_ID Score);
keep Student_ID Score;
*** drop Subject;
run;Code language: SAS (sas)R
In the dplyr R package, we can use the select() function to keep or drop variables. It is very flexible and versatile. If you use ‘-‘ sign with one or multiple variables, R will drop these variables.
Code language: R (r)subset<- score %>% select(student_id, score) subset<- score %>% select(-subject)
Python
In Python, we can use loc[] and iloc[] functions to subset both rows and columns. Similarly, the drop() method for data frames can be used to drop both rows and columns. The syntax is given below.
subset= score.loc[:, ['student_id', 'score']]
sunset= score.drop(columns=[ 'subject'])
subset= score.drop(['subject_id'], axis=1)Code language: Python (python)Summary
Slicing data is a most common task in data analysis. As shown above, we illustrated the various methods to subset data vertically and horizontally in SAS, SQL, R and Python respectively. Under many circumstances, we need to subset in both vertical and horizontal directions, we only need to combine the above methods together to achieve it. It’s easy, you can do it definitely!
Responses